[b01lers 2020]Scarambled
一道很有意思的题。
网页调用了一个youtube的视频。
观察到cookie中有两个特别的值frequency和 tranmissions每一次点击网页中reload 发现frequency会增加1,tranmissions中被kxkxkxkxsh包裹的中间部分也会发生变化。
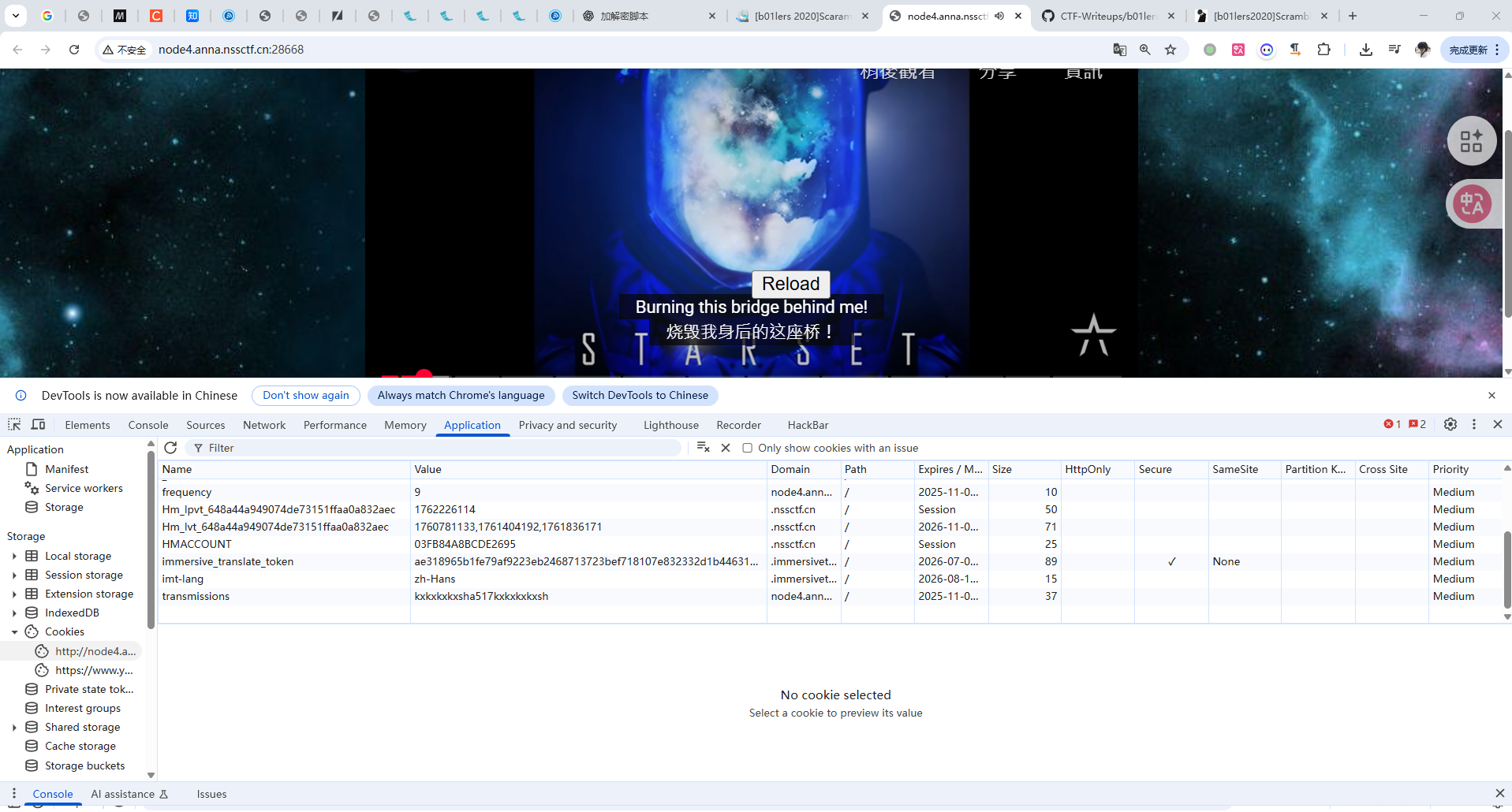
假如把kxkxkxkxsh部分忽略掉,剩下的部分分成三部分:1(红箭头)2(黄箭头)3(黄线)
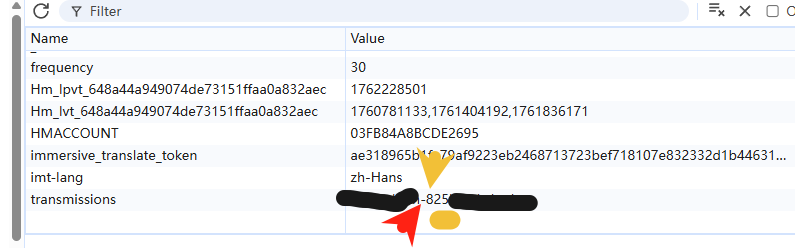
记录下来一些数据,我们会发现

数据中第三部分代表数据第二部分的位置,第一部分代表它存在于第二部分的前一个位置。
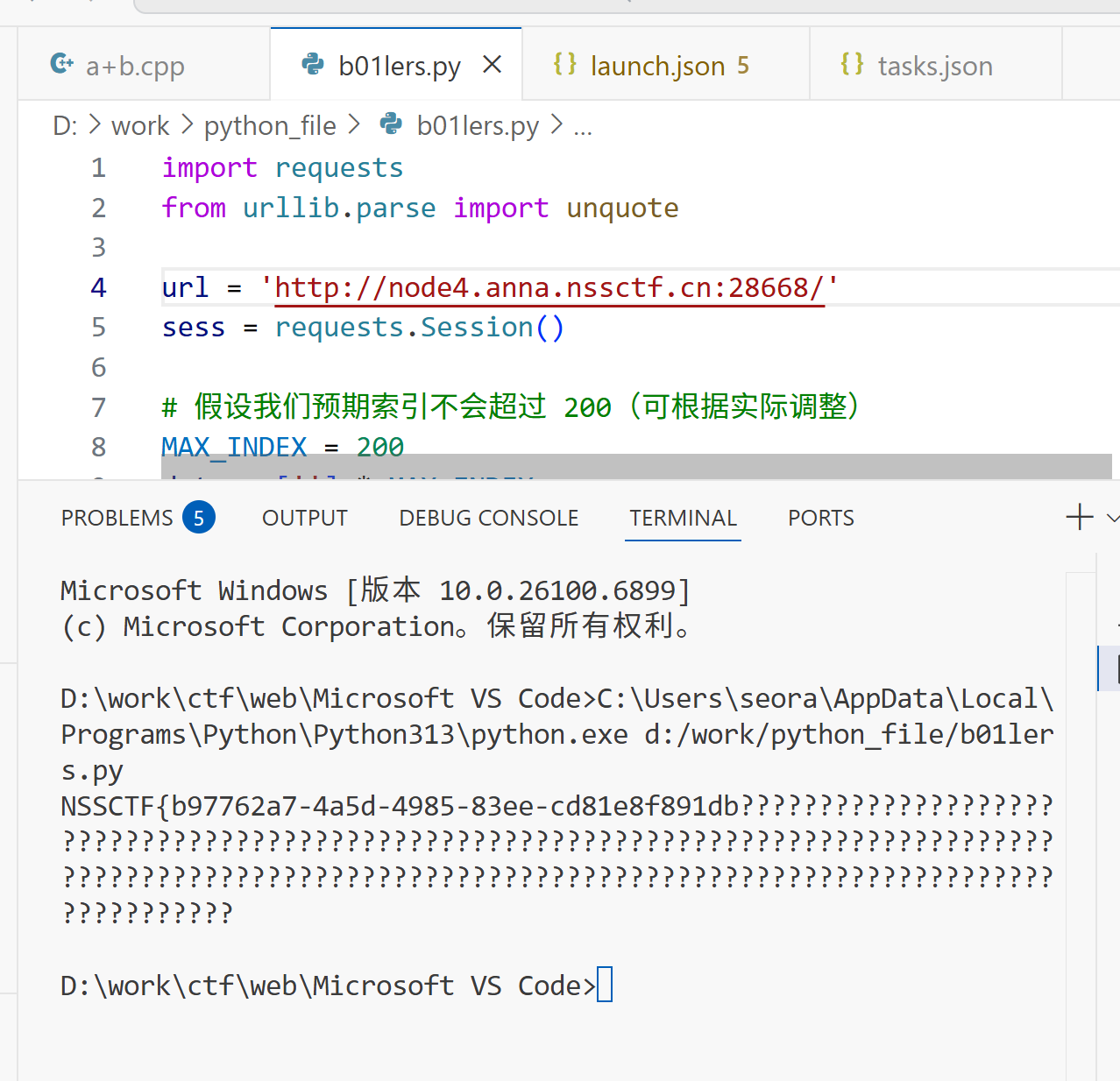
比如说frequency22中: 第三部分20代表4在第二十个位置,那么-在第19个位置,刚好与frequency10对应。甚至可以看到frequency25中显示CT,像是CTF的一部分,猜测完全拼接后会得到flag。发现尝试编写脚本,刷新页面不断获取transmissions中变化的数据,按照规律把他们拼接起来应该能得到flag。
脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import requests
from urllib.parse import unquote
url = 'http://d1653c98-47b9-4f04-b138-71cf1c76520c.node3.buuoj.cn/'
sess = requests.Session()
MAX_INDEX = 200
data = [''] * MAX_INDEX
attempts = 300
for i in range(attempts):
try:
resp = sess.get(url, timeout=5)
except Exception as e:
print(f"[!] 请求失败: {e}")
continue
cj = resp.cookies
cookies_dict = requests.utils.dict_from_cookiejar(cj)
if 'transmissions' not in cookies_dict:
continue
raw = cookies_dict['transmissions'].replace('kxkxkxkxsh', '')
decoded = unquote(raw)
if len(decoded) < 3:
continue
key_str = decoded[2:]
val = decoded[0:1]
if not key_str.isdigit():
continue
idx = int(key_str)
if idx < 0 or idx >= MAX_INDEX:
print(f"[!] 跳过不合理索引: {idx}")
continue
if data[idx] == '':
data[idx] = val
else:
pass
flag = ''.join(ch if ch != '' else '?' for ch in data)
print(flag)
|
references
https://github.com/m3ssap0/CTF-Writeups/blob/master/b01lers%20CTF%202020/Scrambled/README.md